分治算法
1. 概念
分治法(Divide and Conquer),全称为“分而治之”,是一种非常重要且常见的算法策略,通常通过递归来实现。这个策略包含两个主要步骤:“分”和“治”。通过分治策略,我们能够将复杂的问题化繁为简,有效地提升算法的效率和解决问题的能力。
- 分(划分阶段):递归地将原问题分解为两个或多个子问题,直到子问题足够小无法再分时终止。
- 治(合并阶段):从最小子问题的已知解开始,从下到上逐步合并这些子问题的解,最终构建出原问题的完整解。
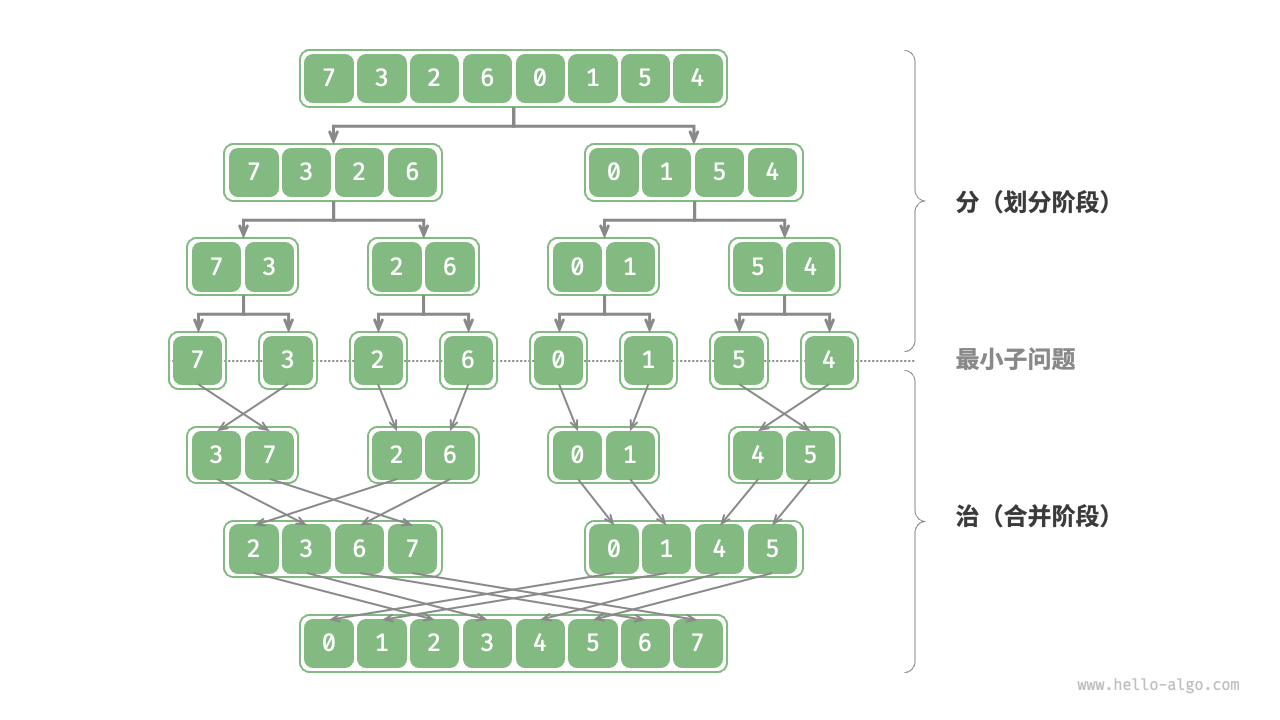
归并排序是分治策略的典型应用之一:
- 分:递归地将原数组(即原问题)划分为两个子数组(即子问题),直到每个子数组只剩下一个元素(即最小子问题)。
- 治:从底向顶合并这些有序的子数组(即子问题的解),最终得到一个有序的完整数组(即原问题的解)。
2. 判断一个问题是否适合使用分治法来解决
判断一个问题是否适合使用分治法来解决,可以参考以下几个标准:
-
问题可以分解:原问题能够被分解为规模更小且相似的子问题,并且这些子问题可以以相同的方式递归地继续划分。
-
子问题是独立的:子问题之间互不依赖,没有重叠,能够独立地解决。
-
子问题的解可以合并:原问题的解可以通过合并子问题的解来得到。
显然,归并排序满足以上三个判断标准:
-
问题可以分解:通过递归的方式将数组(原问题)划分为两个子数组(子问题)。
-
子问题是独立的:每个子数组都可以独立地进行排序(子问题可以独立求解)。
-
子问题的解可以合并:两个有序的子数组(子问题的解)可以合并为一个有序的数组(原问题的解)。
通过这些标准,我们可以判断问题是否适合采用分治策略,从而利用分治法的优势,化繁为简,提高解决问题的效率。
3. 通过分治提升效率
分治策略不仅能有效解决各种算法问题,还能够显著提升算法的效率。在排序算法中,快速排序、归并排序、和堆排序之所以比选择排序、冒泡排序和插入排序更快,正是因为它们应用了分治策略。
这不禁让我们思考:为什么分治策略可以提升算法效率?其背后的逻辑是什么?换句话说,将一个大问题分解为多个子问题、解决子问题、然后将子问题的解合并为原问题的解,这样的步骤为什么比直接解决原问题更高效?这个问题可以从两个角度来探讨:操作数量的减少和并行计算的潜力。
-
操作数量的减少:分治策略通过将大问题分解为更小的子问题,往往能够将问题规模按指数级缩小。由于算法复杂度通常与问题规模成非线性关系,这种缩小会大幅减少所需的操作数量。比如在排序中,分治策略减少了比较和交换的次数,因此相比直接排序更为高效。
-
并行计算的潜力:分治策略将问题拆分成独立的子问题,这些子问题可以同时进行处理。得益于并行计算的能力,可以同时处理多个子问题,从而大幅降低整体计算时间。这在多核处理器和分布式计算环境中尤为显著。
因此,通过减少操作数量和利用并行计算的潜力,分治策略能够在多种算法中实现效率的提升。正是这些底层逻辑,使得分治成为一种强大而高效的算法设计范式。
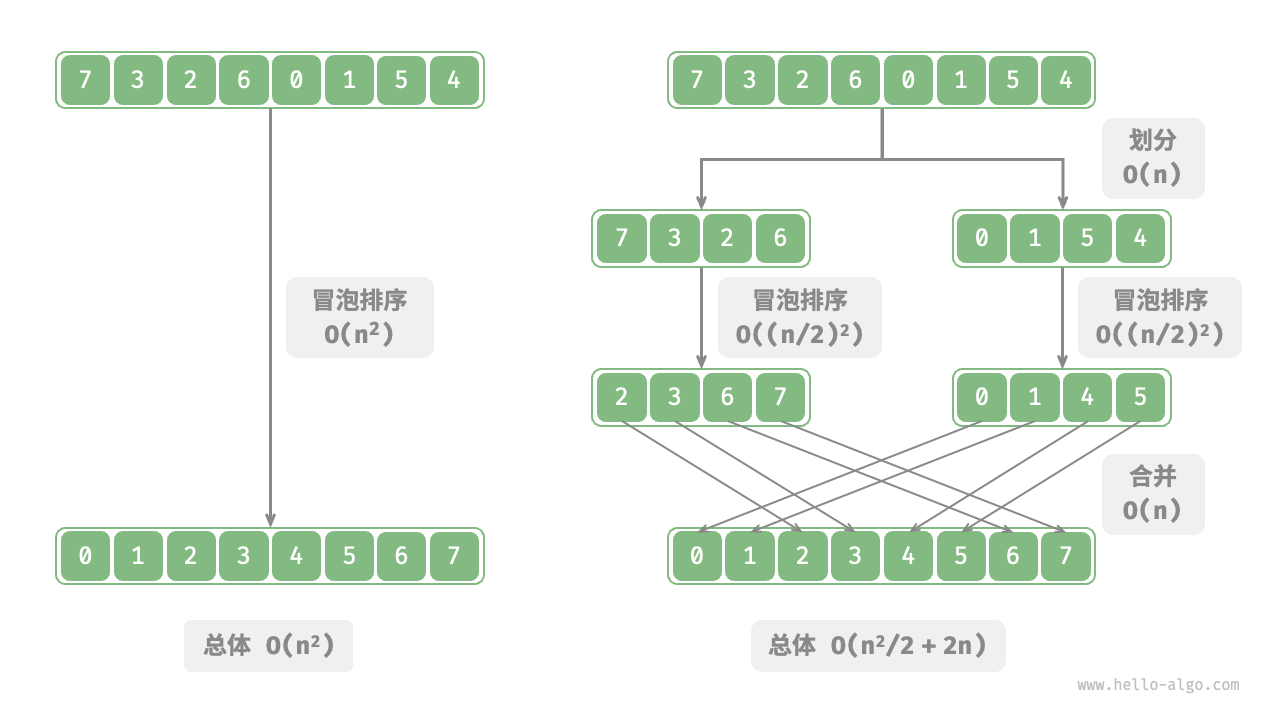
3.1 操作数量优化
以“冒泡排序”为例,对一个长度为 ( n ) 的数组进行排序需要 ( O(n^2) ) 的时间复杂度。假设我们按照图 12-2 的方式,将数组从中间分为两个子数组,则划分操作需要 ( O(n) ) 时间,排序每个子数组各需 ( O((\frac{n}{2})^2) ) 时间,最后合并两个子数组的时间为 ( O(n) )。因此,总体时间复杂度为:
[ O(n) + 2 \times O\left(\left(\frac{n}{2}\right)^2\right) + O(n) = O(n^2) ]
接下来,我们计算以下不等式,其左侧和右侧分别表示划分前后的总操作数量:
[ n^2 > 2 \times \left(\frac{n}{2}\right)^2 + 2n ]
这意味着当 ( n > 4 ) 时,划分后的操作数量较少,因此排序效率更高。需要注意的是,虽然划分后的时间复杂度仍然是 ( O(n^2) ),但复杂度中的常数项减少了。
进一步思考,如果我们继续将子数组从中点再划分为两个更小的子数组,直到每个子数组只剩下一个元素为止,这种思路实际上就是“归并排序”,其时间复杂度为 ( O(n \log n) )。
再进一步设想,如果将原数组划分为 ( k ) 个更小的子数组,而不是仅仅两个,这种情况类似于“桶排序”。这种算法非常适合用于排序海量数据,并且理论上可以将时间复杂度降低到 ( O(n) )。
通过不断地分解问题,我们可以有效优化操作数量,从而提升算法的整体效率。这正是分治策略能够显著提高算法性能的关键所在。
3.2. 并行计算优化
分治策略生成的子问题彼此独立,因此通常可以并行处理。这意味着分治法不仅可以降低算法的时间复杂度,还能为操作系统的并行优化提供支持。
在多核或多处理器环境中,并行优化尤为有效,因为系统能够同时处理多个子问题,从而更加充分地利用计算资源,大幅减少整体运行时间。
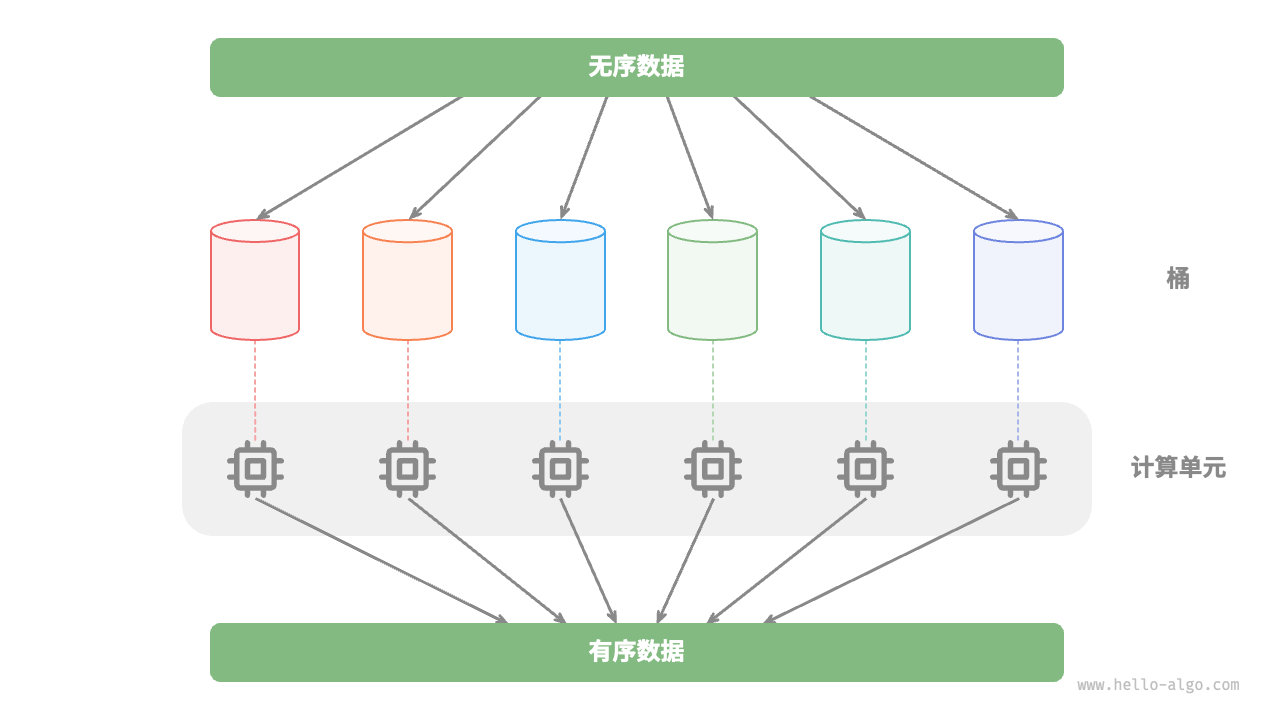
例如,图所示的“桶排序”中,我们将海量数据平均分配到多个桶中,可以将每个桶的排序任务分散到不同的计算单元中独立完成,最后再合并所有桶的排序结果。这种方式充分发挥了并行计算的优势,使得排序任务能够更快速地完成。
通过这种方式,分治策略不仅提高了单机算法的效率,还极大地提升了算法在多处理环境下的并行性能,从而在大数据处理和高性能计算中表现出色。
4. 分治常见应用
分治策略广泛应用于解决许多经典的算法问题,并在算法和数据结构设计中发挥重要作用。
一方面,分治法能够解决许多经典算法问题:
- 寻找最近点对:该算法首先将点集分为两部分,分别找出两部分中的最近点对,然后再找出跨越两部分的最近点对。
- 大整数乘法:例如 Karatsuba 算法,将大整数乘法分解为几个较小整数的乘法和加法,从而降低计算复杂度。
- 矩阵乘法:例如 Strassen 算法,将大矩阵乘法分解为多个小矩阵的乘法和加法,以提高计算效率。
- 汉诺塔问题:汉诺塔问题可以通过递归方式解决,是分治策略的经典应用之一。
- 求解逆序对:在一个序列中,如果前面的数字大于后面的数字,则这两个数字构成一个逆序对。该问题可以利用分治思想,通过归并排序来解决。
另一方面,分治法在算法和数据结构设计中的应用也非常广泛:
- 二分查找:将有序数组从中间分为两部分,根据目标值与中间元素值的比较结果决定排除哪一半区间,并在剩余区间重复相同的二分操作。
- 归并排序:利用分治策略将数组分为更小的子数组,然后将排好序的子数组合并成一个完整的有序数组。
- 快速排序:选择一个基准值,将数组分为两个子数组,一个子数组的元素小于基准值,另一个子数组的元素大于基准值,然后递归地对这两个子数组进行排序,直至每个子数组只剩下一个元素。
- 桶排序:将数据分散到多个桶中,对每个桶内的元素进行排序,最后依次合并桶内元素,形成一个有序数组。
- 树结构:如二叉搜索树、AVL 树、红黑树、B 树、B+ 树等,它们的查找、插入和删除等操作均可视为分治策略的应用。
- 堆:堆是一种特殊的完全二叉树,其操作,如插入、删除和堆化,实际上都蕴含了分治思想。
- 哈希表:尽管哈希表并不直接应用分治法,但某些哈希冲突解决方案间接应用了分治策略,例如,当链式地址法中的长链表被转化为红黑树时,可以提升查询效率。
由此可见,分治法作为一种“润物细无声”的算法思想,广泛而深刻地隐含在各类算法和数据结构中,有效提升了它们的性能和效率。
5. 分治搜索策略
我们已经了解到,搜索算法主要分为两大类:
- 暴力搜索:通过遍历数据结构来实现,时间复杂度通常为 ( O(n) )。
- 自适应搜索:利用特定的数据组织形式或先验信息,时间复杂度可以优化到 ( O(\log n) ) 甚至更低。
实际上,时间复杂度为 ( O(\log n) ) 的搜索算法通常是基于分治策略实现的,例如二分查找和树结构。
-
二分查找:每一步都将问题(在数组中查找目标元素)分解为一个较小的问题(在数组的一半中查找目标元素)。这个过程会持续进行,直到数组为空或找到目标元素为止。
-
树结构:树是分治思想的典型代表。在二叉搜索树、AVL 树、堆等数据结构中,各种操作的时间复杂度通常为 ( O(\log n) )。
以下是二分查找的分治策略:
-
问题可以分解:二分查找递归地将原问题(在整个数组中查找)分解为子问题(在数组的一半中查找),这是通过比较中间元素和目标元素来实现的。
-
子问题是独立的:在二分查找中,每次只处理一个子问题,该子问题的求解过程不受其他子问题的影响。
-
子问题的解无须合并:二分查找的目标是找到特定的元素,因此不需要将子问题的解合并。当某个子问题得到解决时,原问题也随之解决。
分治策略之所以能够显著提升搜索效率,根本原因在于暴力搜索每轮只能排除一个选项,而分治搜索每轮可以排除一半的选项。因此,分治法通过减少操作量和增加效率,成为了搜索问题中不可或缺的重要策略。
5.2. 基于分治实现二分查找
在之前的章节中,我们介绍了通过迭代(递推)来实现二分查找的方法。现在,我们将基于分治策略(递归)来实现二分查找。
问题描述
给定一个长度为 ( n ) 的有序数组 nums,其中所有元素都是唯一的。目标是查找元素 target。
分治策略
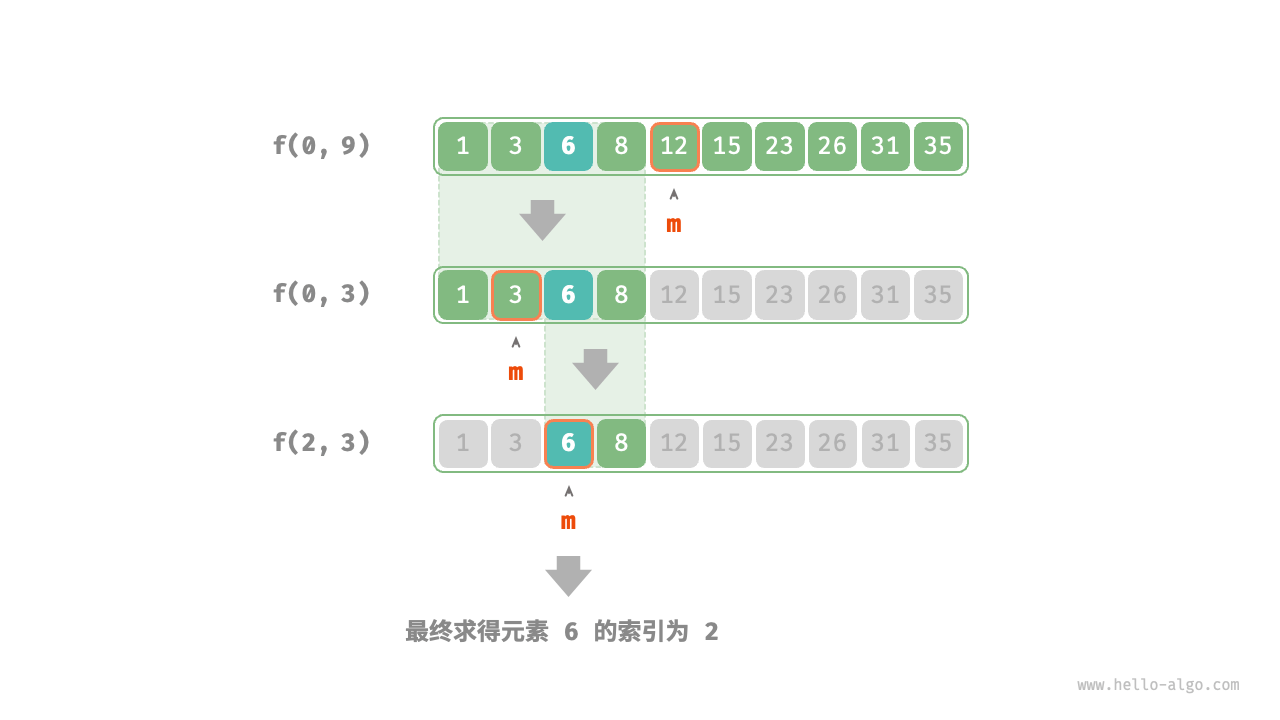
从分治的角度来看,我们将搜索区间 ( [l, r] ) 对应的子问题记为 ( P(l, r) )。
以原问题 ( P(0, n-1) ) 为起点,通过以下步骤进行二分查找:
-
计算中点:计算搜索区间 ( [l, r] ) 的中点 ( m ),并根据中点元素的值排除一半的搜索区间。
-
递归求解:根据中点的值递归求解规模减小一半的子问题,可能是 ( P(l, m-1) ) 或 ( P(m+1, r) )。
-
循环迭代:重复第 1 步和第 2 步,直到找到
target或者搜索区间为空(即无法找到target时返回)。
通过分治的递归策略,我们能够将问题不断分解,缩小搜索范围,从而高效地查找到目标元素。
下面是基于分治策略(递归)实现二分查找的 Python 代码:
def binary_search(nums, target):
def search(l, r):
# 基本情况:当搜索区间为空时,返回 -1 表示未找到
if l > r:
return -1
# 计算中点索引
m = l + (r - l) // 2
# 如果中点元素就是目标元素,返回其索引
if nums[m] == target:
return m
# 如果中点元素大于目标元素,递归搜索左半部分
elif nums[m] > target:
return search(l, m - 1)
# 如果中点元素小于目标元素,递归搜索右半部分
else:
return search(m + 1, r)
# 调用递归函数,从整个数组的起始点开始搜索
return search(0, len(nums) - 1)
# 示例用法
nums = [1, 2, 4, 5, 7, 8, 10]
target = 5
result = binary_search(nums, target)
print(f"元素 {target} 的索引为: {result}") # 输出: 元素 5 的索引为: 3
代码说明:
binary_search函数是主函数,负责调用内部的递归函数search。search(l, r)是递归函数,它接收当前的搜索区间边界l和r。- 通过递归不断缩小搜索区间,当找到目标元素时返回其索引;如果搜索区间为空(即
l > r),则返回-1,表示目标元素不存在于数组中。
这个实现利用了分治策略,通过递归方式将搜索范围不断缩小,直到找到目标元素或者确认目标元素不存在。